Boosting
June 16, 2019
Boosting
集成多个模型,每个模型都在尝试增强(Boosting)整体的效果。
Ada Boosting
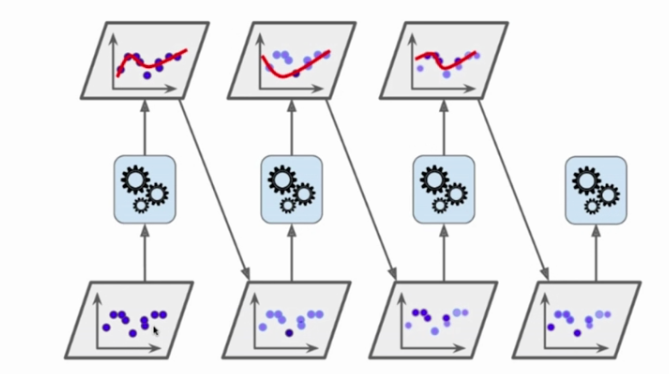
如上图,Ada Boosting 的工作过程如下:
- 一开始所有的样本点权值都一样
- 某种算法进行 fit 后,得到的模型对其中已成功预测,或者偏差不大的样本降低权值
- 再次使用某种算法,对权值调整后的样本进行训练
- 再次调整样本权值,降低预测误差不大的样本的权值
- 再次使用某种模型进行训练
如此往复,我们得到了许多子模型,其训练使用的样本数据是一样的,只是在不断调整权值得到子样本上训练。
每次训练都可以看作是对上次训练结果的增强(Boosting)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
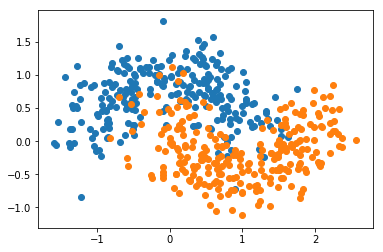
X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=666)
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=500)
ada_clf.fit(X_train, y_train)
AdaBoostClassifier(algorithm=’SAMME.R’, base_estimator=DecisionTreeClassifier(class_weight=None, criterion=’gini’, max_depth=2, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter=’best’), learning_rate=1.0, n_estimators=500, random_state=None)
ada_clf.score(X_test, y_test)
0.872
Gradient Boosting
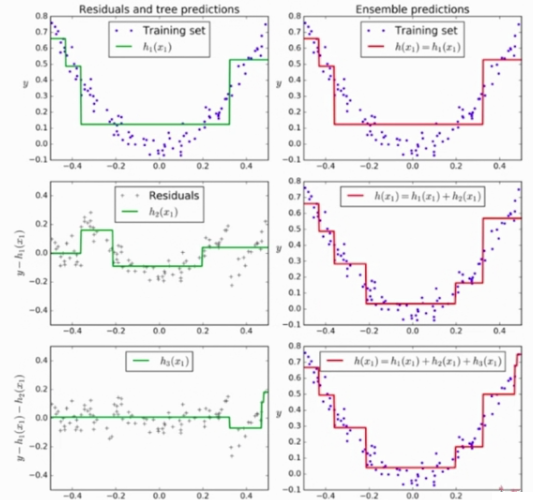
- 训练一个模型m1,产生错误e1
- 针对e1训练第二个模型m2,产生错误e2
- 针对e2训练第三个模型m3,产生错误e3……
最终预测结果是:m1 + m2 + m3……
它是以决策树又基本的
下图左侧是产生的错误和训练的模型,右侧是模型叠加(m1 + m2 + m3……)
from sklearn.ensemble import GradientBoostingClassifier
gd_clf = GradientBoostingClassifier(max_depth=2, n_estimators=500)
gd_clf.fit(X_train, y_train)
GradientBoostingClassifier(criterion=’friedman_mse’, init=None, learning_rate=0.1, loss=’deviance’, max_depth=2, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=500, n_iter_no_change=None, presort=’auto’, random_state=None, subsample=1.0, tol=0.0001, validation_fraction=0.1, verbose=0, warm_start=False)
gd_clf.score(X_test, y_test)
0.896
回归问题
同样的使用 regressor 解决