Cross Validation
April 24, 2019
验证数据集和交叉验证
测试数据集的问题:
针对特定的测试数据集过拟合
解决办法:
将数据集分为三部分,训练数据集、验证数据集、测试数据集
针对验证数据集进行调参使得,训练数据训练的模型在验证数据集已经达到最佳,再将测试数据集作为衡量最终模型性能的数据集。
此时验证数据集的作用是调整超参数用的数据集。
其中训练数据集和验证数据集都参与了模型的构建。
但是这么做还是有问题:随机?
解决方案:
交叉验证
交叉验证
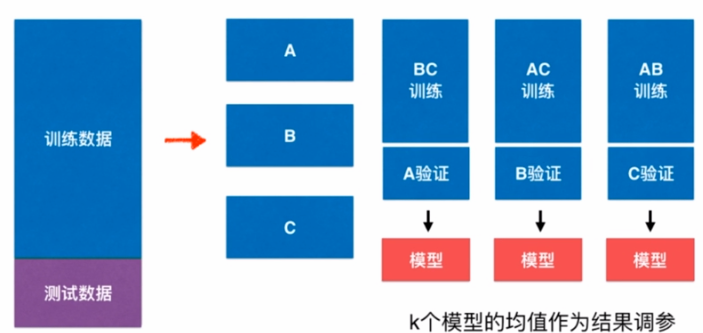
如上图:
- 将数据集分为训练数据集和测试数据集
- 再将训练数据集分为k个数据集,这k个数据集分别作为验证数据集,其他数据集作为训练数据集进行训练得出k个模型
- 根据k个模型的均值作为结果进行调参
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
测试train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
best_score, best_p, best_k = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_score, best_p, best_k = score, p, k
print("Best k =", best_k)
print("Best p =", best_p)
print("Best score =", best_score)
Best k = 3 Best p = 4 Best score = 0.9860917941585535
使用交叉验证
from sklearn.model_selection import cross_val_score
knn_clf = KNeighborsClassifier()
cross_val_score(knn_clf, X_train, y_train, cv=5)
array([0.99543379, 0.97716895, 0.97685185, 0.98130841, 0.97142857])
best_score, best_p, best_k = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
scores = cross_val_score(knn_clf, X_train, y_train)
score = np.mean(scores)
if score > best_score:
best_score, best_p, best_k = score, p, k
print("Best k =", best_k)
print("Best p =", best_p)
print("Best score =", best_score)
Best k = 2 Best p = 2 Best score = 0.9823599874006478
best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=2, p=2)
best_knn_clf.fit(X_train, y_train)
best_knn_clf.score(X_test, y_test)
0.980528511821975
回顾网格搜索
from sklearn.model_selection import GridSearchCV
params_grid = {
"weights":["distance"],
"n_neighbors":[i for i in range(2, 11)],
"p":[i for i in range(1,6)]
}
grid_search = GridSearchCV(KNeighborsClassifier(), params_grid, verbose=1, cv=3)
grid_search.fit(X_train, y_train)
Fitting 3 folds for each of 45 candidates, totalling 135 fits
| [Parallel(n_jobs=1)]: Done 135 out of 135 | elapsed: 1.5min finished |
GridSearchCV(cv=3, error_score=’raise’, estimator=KNeighborsClassifier(algorithm=’auto’, leaf_size=30, metric=’minkowski’, metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights=’uniform’), fit_params=None, iid=True, n_jobs=1, param_grid={‘weights’: [‘distance’], ‘n_neighbors’: [2, 3, 4, 5, 6, 7, 8, 9, 10], ‘p’: [1, 2, 3, 4, 5]}, pre_dispatch=’2*n_jobs’, refit=True, return_train_score=’warn’, scoring=None, verbose=1)
grid_search.best_score_
0.9823747680890538
grid_search.best_params_
{‘n_neighbors’: 2, ‘p’: 2, ‘weights’: ‘distance’}
grid_search.best_estimator_.score(X_test, y_test)
0.980528511821975
总结 k-folds 交叉验证
把训练数据集分成k份,
成为 k-folds cross validation
缺点:每次训练k个模型,相当于整体性能慢了 k 倍
留一法 LOO-CV
若训练集有m个样本,则把训练集分成k=m份,进行交叉验证,成为留一法
Leave-One-Out Cross Validation
完全不受随机的影响,最接近模型真正的性能指标
缺点:计算量巨大